


Published on Apr 23, 2019
Updated on Feb 20, 2020
Create superior customer experiences to enhance competitive advantage.
Go from zero to breakthrough with scalable, future-proof solutions.
Harness deep tech for smarter solutions and maximum impact.
Accelerate value delivery with powerful pre-built digital tools.
Help businesses connect with an internet first generation.
Test the smarter way: where precision meets efficiency.
Unlock real-time and personalized customer journeys for mobile first generation.
Turn data into decisive action with scalable AI infrastructure.
Design agile digital foundations that scale with tomorrow's business needs.
Build new-age architecture for maximum efficiency and hyper-growth.
Fine-tune your cloud infrastructure for peak performance.

All
Customer Experience
Mantra
Application Development
Insurtech
Digital Health
Insurance
Deep-Tech
AgriTech(1)
Augmented Reality(21)
Clean Tech(9)
Customer Journey(17)
Design(45)
Solar Industry(8)
User Experience(68)
Edtech(10)
Events(34)
HR Tech(3)
Interviews(10)
Life@mantra(11)
Logistics(6)
Manufacturing(3)
Strategy(18)
Testing(9)
Android(48)
Backend(32)
Dev Ops(11)
Enterprise Solution(33)
Technology Modernization(9)
Frontend(29)
iOS(43)
Javascript(15)
AI in Insurance(38)
Insurtech(66)
Product Innovation(59)
Solutions(22)
E-health(12)
HealthTech(24)
mHealth(5)
Telehealth Care(4)
Telemedicine(5)
Artificial Intelligence(153)
Bitcoin(8)
Blockchain(19)
Cognitive Computing(8)
Computer Vision(8)
Data Science(23)
FinTech(51)
Banking(7)
Intelligent Automation(27)
Machine Learning(48)
Natural Language Processing(14)
Convolutional Neural Networks (CNN) have come a long way in conveniently identifying objects in images and videos. Networks like VGG19, ResNet, YOLO, SSD, R-CNN, DensepathNet, DualNet, Xception, Inception, PolyNet, MobileNet, and many more have evolved over time. Their range of applications lies in detecting space availability in a parking lot, satellite image analysis to track ships and agricultural output, radiology, people count, detecting words in vehicle license plates and storefronts, circuits/machinery fault analysis, medical diagnosis, etc.
Facebook AI Research (FAIR) has recently published RetinaNet architecture which uses Feature Pyramid Network (FPN) with ResNet. This architecture demonstrates higher accuracy in situations where speed is not really important. RetinaNet is built on top of FPN using ResNet.
Google offers benchmark comparison to calculate tradeoff between speed and accuracy of various networks using MS COCO dataset to train the models in TensorFlow. It gives us a benchmark to understand the best model that provides a balance between speed and accuracy. According to researchers, Faster R-CNN is more accurate, whereas R-FCN and FCN show better inference time (i.e. their speed is higher). Inception and ResNet are implementations of Faster R-CNN. MobileNet is an implementation of SSD.
Faster R-CNN implementations show an overall mAP (mean average precision) of around 30, which is highest for feature extraction. And, at the same time, its accuracy is also highest at around 80.5%. MobileNet R-FCN implementation has a lower mAP of around 15. Therefore, its accuracy drops down to about 71.5%.
Thus, we can say — SSD implementations work best for detecting larger objects whereas, Faster R-CNN and R-FCN are better at detecting small objects.
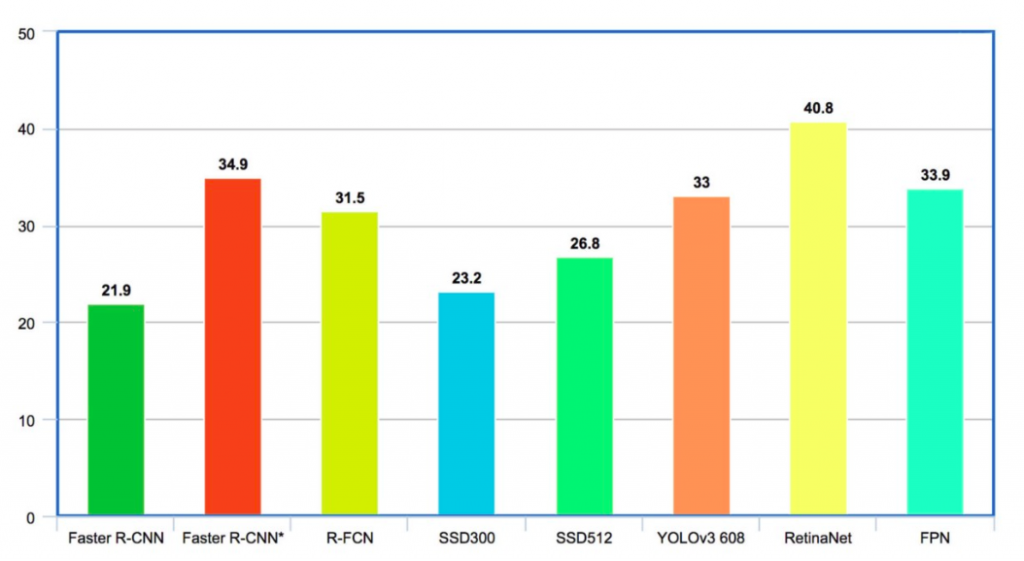
On the COCO dataset, Faster R-CNN has average mAP for IoU (intersection-over-union) from 0.5 to 0.95 (mAP@[0.5, 0.95]) as 21.9% . R-FCN has mAP of 31.5% . SSD300 and SSD512 have mAPs of 23.2 and 26.8 respectively . YOLO-V2 is at 21.6% whereas YOLO-V3 is at 33% . FPN delivers 33.9% . RetinaNet stands highest at 40.8%.
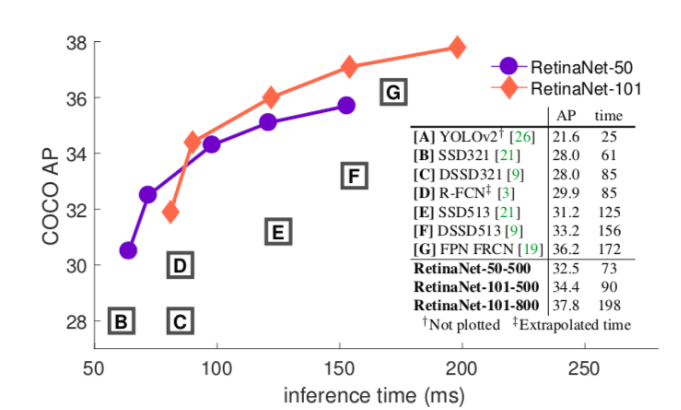
A One-stage detector scans for candidate objects sampled for around 100000 locations in the image that densely covers the spatial extent. This does not let the class balance between background and foreground.
A Two-stage detector first narrows down the number of candidate objects on up to 2000 locations and separates them from the background in the first stage. It then classifies each candidate object in the second stage, thus managing the class balance. But, because of the smaller number of locations in the sample, many objects might escape detection.
Faster R-CNN is an implementation of the two-stage detector. RetinaNet, an implementation of one stage detector addresses this class imbalance and efficiently detects all objects.
This function focuses on training on hard negatives. It is defined as-
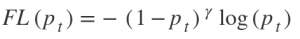
Where,
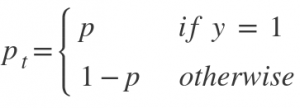
and p = sigmoid output score.
The greeks are hyperparameters.
When a sample classification is inappropriate and pₜ is small, it does not affect the loss. Gamma is a focusing parameter and adjusts the rate at which the easy samples are down-weighted. Samples get down-weighted when their classification is inappropriate and pₜ is close to 1. When gamma is 0, the focal loss is close to the cross-entropy loss. Upon increasing gamma, the effect of modulating factor also increases.
The new loss function called Focal loss increases the accuracy significantly. Essentially it is a one-stage detector Feature Pyramid Network with Focal loss replacing the cross-entropy loss.
Hard negative mining in a single shot detector and Faster R-CNN addresses the class imbalance by downsampling the dominant samples. On the contrary, RetinaNet addresses it by changing the weights in the loss function. The following diagram explains the architecture.
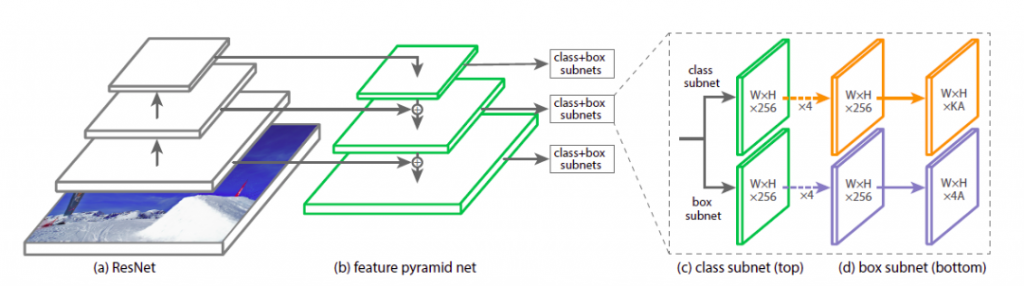
Here, deep feature extraction uses ResNet. Using FPN on top of ResNet further helps in constructing a multi-scale feature pyramid from a single resolution image. FPN is fast to compute and works efficiently on multiscale.
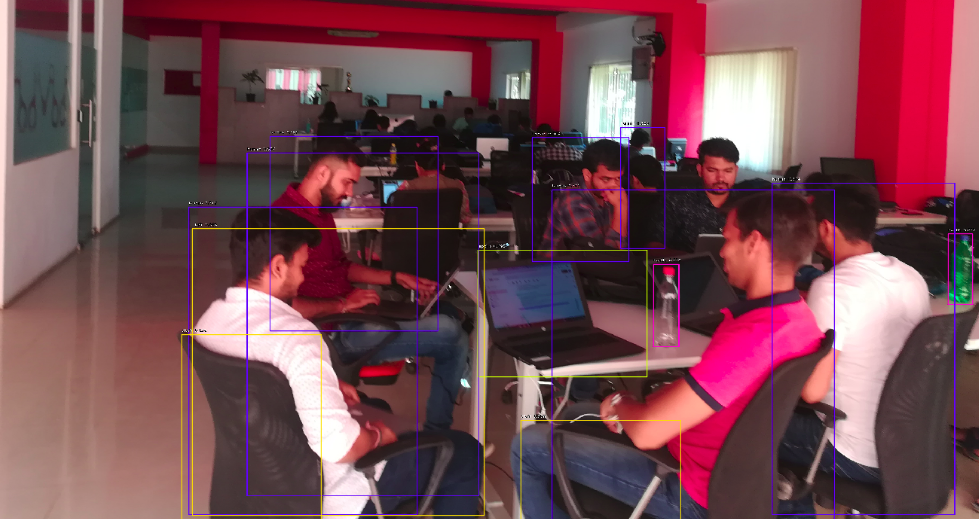
We used ResNet50-FPN pre-trained on MS COCO to identify humans in the photo. The threshold is set above a score of 0.5. The following images show the result with markings and confidence values.


We further tried to detect other objects like chairs.

Conclusion: It’s great to know that training on the COCO dataset can detect objects from unknown scenes. The object detection in the scenes took 5-7 seconds. So far, we have put filters of human or chair in results. RetinaNet can detect all the identifiable objects in the scene.
The different objects detected with their score are listed below-
| human | 0.74903154 |
| human | 0.7123633 |
| laptop | 0.69287986 |
| human | 0.68936586 |
| bottle | 0.67716646 |
| human | 0.66410005 |
| human | 0.5968385 |
| chair | 0.5855772 |
| human | 0.5802317 |
| bottle | 0.5792091 |
| chair | 0.5783555 |
| chair | 0.538948 |
| human | 0.52267283 |
Next, we will be interested in working on a model good in detecting objects in the larger depth of the image, which the current ResNet50-FPN could not do.
About author: Harsh Vardhan is a Tech Lead in the Development Department of Mantra Labs. He is integral to AI-based development and deployment of projects at Mantra Labs.
RetinaNet is a type of CNN (Convolutional Neural Network) architecture published by Facebook AI Research also known as FAIR. It uses the Feature Pyramid Network (FPN) with ResNet. RetinaNet is widely used for detecting objects in live imagery (real-time monitoring systems). This architecture demonstrates a high-level of accuracy, but with a little compromise in speed. In the experiment we conducted, it took 5-7 seconds for object detection in live scenes.
RetinaNet model comprises of a backbone network and two task-specific sub-networks. The backbone network is a Feature Pyramid Network (FPN) built on ResNet. It is responsible for computing a convolution feature (object) from the input imagery. The two subnetworks are responsible for the classification and box regression, i.e. one subnet predicts the possibility of the object being present at a particular spatial location and the other subnetwork outputs the object location for the anchor box.
The focal loss function focuses on training on hard negatives. In other words, the focal loss function is an algorithm for improving Average Precision (AP) in single-stage object detectors. It is defined as-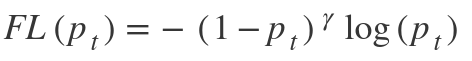
Single Shot Detector (SSD) can detect multiple objects in an image in a single shot, hence the name.
The beauty of SSD networks is that it predicts the boundaries itself and has no assigned region proposal network. SSD networks can predict the boundary boxes and classes from feature maps in just one pass by using small convolutional filters.
Deep Learning uses Convolutional neural networks (CNN) for analyzing visual imagery. It consists of an input and output layer and multiple intermediate layers. In CNN programming, the input is called a tensor, which is usually an image or a video frame. It passes through the convolutional layer forming an abstract feature map identifying different shapes.
The process of combining region proposals with CNN is called as R-CNN. Region proposals are the smaller parts of the original image that have a probability of containing the desired shape/object. The R-CNN algorithm creates several region proposals and each of them goes to the CNN network for better dense shape detection.
Residual Neural Network (ResNet) utilizes skip connections to jump over some layers. Classical CNNs do not perform when the depth of the network increases beyond a certain threshold. Most of the ResNet models are implemented with double or triple layer skips with batch normalization in between. ResNet helps in the training of deeper networks.
You only look once (YOLO) is a real-time object detection system. It is faster than most other neural networks for detecting shapes and objects. Unlike other systems, it applies neural network functions to the entire image, optimizing the detection performance.
It is Facebook’s AI Research arm for understanding the nature of intelligence and creating intelligent machines. The main research areas at FAIR include Computer Vision, Conversational AI, Integrity, Natural Language Processing, Ranking and Recommendations, System Research, Theory, Speech & Audio, and Human & Machine Intelligence.
Feature Pyramid Network (FPN) is a feature extractor designed for achieving speed and accuracy in detecting objects or shapes. It generates multiple feature map layers with better quality information for object detection.
Common Objects in Context (COCO) is a large-scale dataset for detecting, segmenting, and captioning any object.
Fully Convolutional Network (FCN) transforms the height and width of the intermediate layer (feature map) back to the original size so that predictions have a one-to-one correspondence with the input image.
R-FCN corresponds to a region-based fully convolutional network. It is mainly used for feature detection. R-FCN comprises region-based feature maps that are independent of region proposals (ROI) and carry computation outside of ROIs. It is much simpler and about 20 times faster than R-CNN.
It is an open-source software library developed by Google Brain for a range of dataflow and differential programming applications. It is also useful in neural network programming.
Also read – How are Medical Images shared among Healthcare Enterprises
Knowledge thats worth delivered in your inbox
Sales success today isn’t about luck or lofty goals—it’s about having the right tools in your team’s hands, wherever they go. Following our earlier in-depth exploration of sales technology, we will now examine how cutting-edge sales apps are becoming the backbone of modern industries, transforming complex workflows into seamless, growth-driving machines.
From retail to healthcare, logistics to real estate, businesses are deploying sales applications to enhance operational transparency, cut redundant tasks, and build intelligent sales ecosystems. These tools are not only digitizing workflows—they’re driving growth, improving engagement, and redefining how field teams operate.
One app. Five workflows. Zero friction.
A leading insurance brand relaunched their app—a sleek, powerful sales companion that’s turning everyday agents into top performers.
No more paperwork. More time to sell.
Here’s what changed:
The result? A field team that moves faster, sells better, and works smarter.
Field sales agents in retail, especially FMCG, used to rely on gut instinct. Now, with intelligent sales applications:
Healthcare leaders don’t need more reports—they need better visibility from the field. Whether it’s engaging hospital networks, onboarding clinics, or enabling diagnostics at the last mile, everything needs precision, compliance, and clarity.
Mantra Labs helped a leading healthcare enterprise design a sales app that integrates knowledge, compliance, performance, and recognition, turning frontline agents into informed, aligned, and empowered brand advocates.
Here’s what it delivers:
Now, the field agents aren’t just connected—they’re aligned, upskilled, and accountable.
For real estate agents, timing and personalization are everything. Sales applications are evolving to include:
Field agents in logistics are switching from clipboards to real-time command centers on mobile. Modern sales applications offer:
Here’s what’s pushing the next wave of innovation:
Sales Applications are not just tactical tools. They’re platforms for transformation. With the right design, integrations, and analytics, they:
The future of field sales lies in intuitive, AI-driven applications that adapt to every industry’s nuances. At Mantra Labs, we work closely with enterprises to custom-build sales applications that align with business objectives and ground-level realities.
If your agents still rely on Excel trackers and daily call reports, it’s time to reimagine your sales operations. Let us help you bring your field operations into the future—with tools that are fast, field-tested, and built for scale.
Knowledge thats worth delivered in your inbox



Our Sales Team will be in touch with you shortly.

Hello Stranger! Please fill in a few details,and you’ll receive a link to this case study.
 We have mailed you this case study.
We have mailed you this case study.
Thanks for subscribing.
